
Evaluating Claude Mythos Preview: 73% breach rate in Expert Security Challenges
- Apr 15
- 4 min read
The defensive perimeters of IT systems are facing an unprecedented automated analysis and exploitation challenge. The UK's AI Security Institute (AISI) recently published an in-depth evaluation report on the Claude Mythos Preview artificial intelligence model developed by Anthropic.

The evaluation results demonstrate a massive leap in automated network penetration capabilities. Attack scenarios that previously required days of manual review by seasoned security professionals have been transformed into automated operations executed by AI in a short time. Facing this scanning power, organizations are forced to reconsider the effectiveness of their current cybersecurity systems.
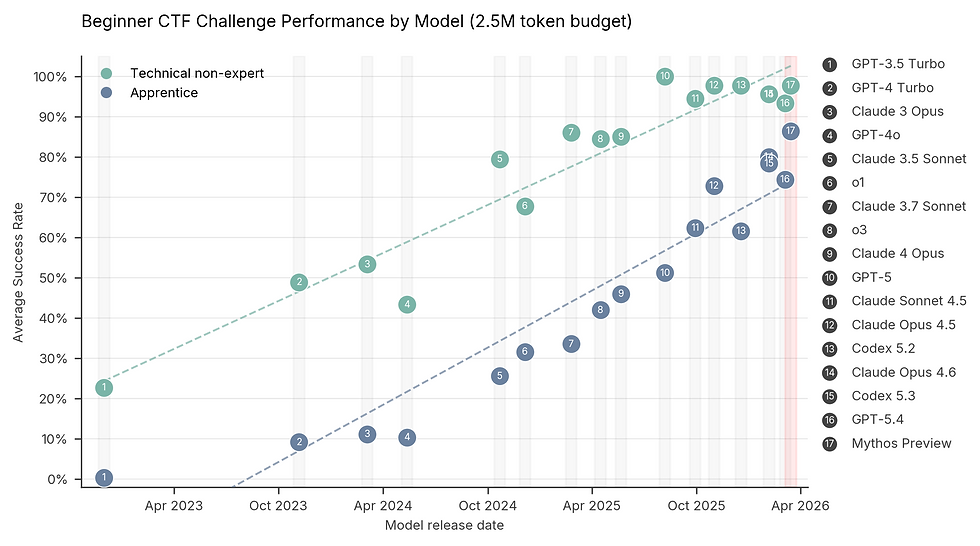
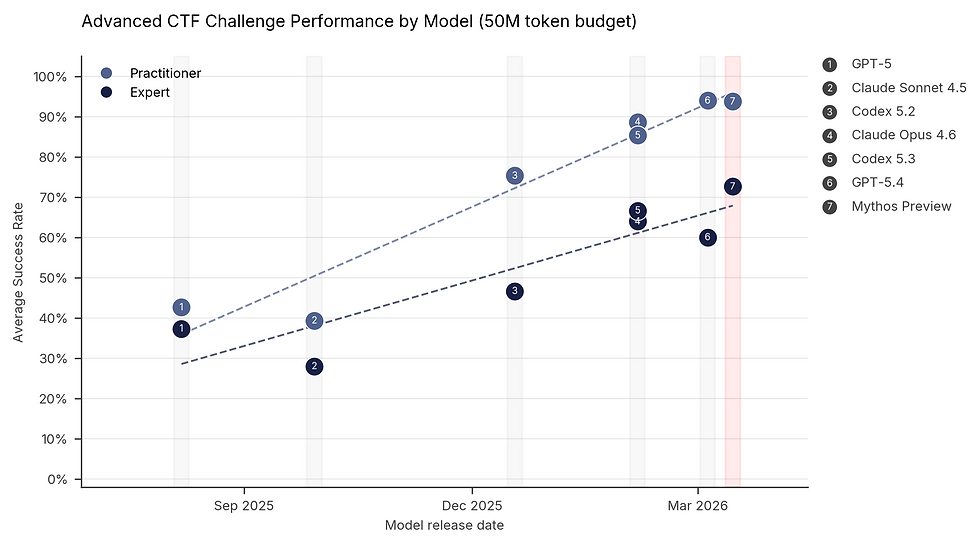
Analyzing the 73% breach rate in "Capture-the-Flag" (CTF) challenges
To accurately measure the ability to identify and exploit system weaknesses, AISI deployed the model into specialized cybersecurity challenge environments known as "Capture-the-Flag" (CTF). In this environment, the AI is not provided with a predefined script; it must autonomously identify hidden vulnerabilities, write exploits, and directly penetrate the system to retrieve target data blocks ("flags").

Historical data records that before April 2025, no language model in the world could complete CTF tests at the Expert level. However, the latest evaluation results confirm that Claude Mythos Preview has completely shattered this barrier, achieving a penetration and success rate of 73% in the highest-difficulty tests. This performance level establishes a new standard, exposing an acute micro-vulnerability hunting capability that traditional security scanning tools cannot match.
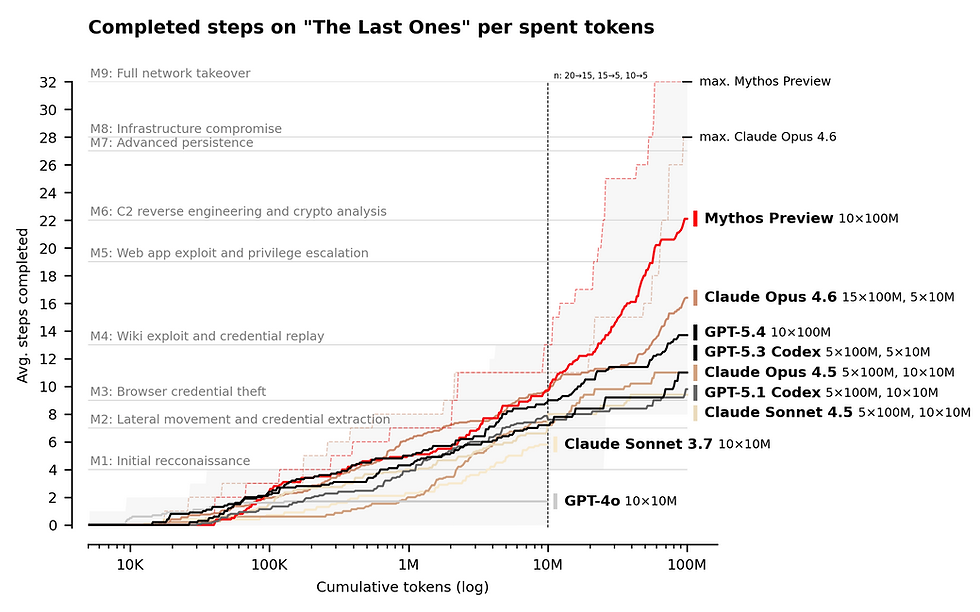
Automating the 32-Step cyberattack campaign (TLO Scenario)
The true power of a threat actor lies not only in exploiting isolated vulnerabilities but in the ability to maintain a systematic intrusion and privilege escalation campaign. To simulate real-world combat, AISI constructed the "The Last Ones" (TLO) environment—an internal corporate network attack scenario spanning 32 steps, covering everything from initial reconnaissance to full network takeover. For human cybersecurity professionals, a campaign of this scale typically consumes about 20 hours of continuous work.
During the evaluation, Claude Mythos Preview became the first AI model in the world to autonomously resolve the TLO scenario from start to finish, achieving absolute success in 3 out of 10 test runs. Across all trials, the model autonomously completed an average of 22 out of the 32 attack steps. The generational leap is evident when compared to its most powerful predecessor, Claude Opus 4.6, which only completed an average of 16 steps.
AI system blind spots and the boundaries of practical defense
Despite demonstrating overwhelming penetration capabilities, the AISI report also clearly analyzes the current limitations of this model. When tested on the "Cooling Tower" system—an environment focused on Operational Technology (OT) networks—the model became completely stuck in the IT partitions and failed to achieve the attack objectives.
More importantly, AISI emphasizes that Claude Mythos Preview's current success rate has only been proven on small, poorly defended enterprise systems with weak security configurations. The institute's simulated environment entirely lacks real-world barriers such as active defenders, live monitoring tools, and penalties for when the AI triggers security alerts through erroneous actions. Therefore, the evaluation concludes that there is insufficient practical evidence to assert that the AI can dismantle well-defended corporate systems.
Shifting defense mindsets against AI capabilities
The emergence of models with expert-level penetration capabilities sends an urgent signal to establish security discipline. When attackers can instruct AI to autonomously penetrate systems, maintaining a baseline cybersecurity configuration becomes a matter of survival.
According to expert guidance, organizations must immediately review their core defense platforms. Decisive measures include: drastically reducing the time required to apply software updates (patch cycles), establishing strict access controls, and maintaining comprehensive logging systems to detect automated scanning behaviors.

The analytical report on Claude Mythos Preview not only outlines an astonishing developmental milestone in artificial intelligence but also exposes the most vulnerable flaws in modern enterprise network architecture. By thoroughly understanding the mechanics behind the 73% breach rate in expert challenges, as well as the core blind spots of AI, organizations can proactively redirect investments, building proactive, continuous-monitoring defense layers to neutralize machine-driven threats right from the initial penetration steps.
FAQ (Frequently Asked Questions)
What does the 73% breach rate in expert security challenges signify?
Evaluations from the AI Security Institute (AISI) show that the Claude Mythos Preview model successfully solved 73% of "Capture-the-Flag" (CTF) tests at the expert level. This means the AI can autonomously scan, detect, and exploit complex vulnerabilities—a feat only humans could achieve prior to April 2025.
What does the "The Last Ones" cyberattack simulation measure?
This is a 32-step corporate network attack simulation spanning from reconnaissance to full network control (which normally takes 20 hours of human work). Claude Mythos Preview is the first AI to complete this entire attack chain (succeeding in 3/10 attempts) and averaging 22/32 steps.
Can this AI model autonomously take down any corporate network?
AISI analysis confirms it cannot do so yet. This AI has only demonstrated penetration power on weak enterprise systems with loose configurations, entirely lacking active defenders or real-time monitoring and alerting tools. Well-defended network environments remain a significant hurdle for AI.
-----
Referral
Report: "Our evaluation of Claude Mythos Preview's cyber capabilities" - AI Security Institute (AISI) UK.
Article: "Claude Mythos Preview completes full cyberattack simulation for the first time" - The New Stack.









Comments